Linux [re]install CUDA - Linux 安装和使用 CUDA
简便安装方法
此文档来源于Jermine的个人blog : https://jermine.vdo.pub/linux/ubuntu-16.04-reinstall-cuda/
推荐两种玩法:
注意 : 由于tensorflow的GPU版本依赖nvidia的cuda、cudnn库,因此一般需要包含cuda和cudnn的链接库文件,普遍做法是通过主机安装cudnn、cuda的方式。这里还有另外两种方式可以选择:
方法一:使用nvidia-docker (我认为是棒的方式)
由于程序运行于容器之中,所以镜像中一般都是带有CUDA、CUDNN库的,因此只需要在docker所在的主机上安装显卡驱动即可,无需费太大力气去安装cuda、cuddn之类的东西。 参照: https://jermine.vdo.pub/linux/linux%E5%AE%89%E8%A3%85nvidia-docker/ 进行安装
方法二:使用Miniconda (裸金属主机下最棒的方式)
采用miniconda安装GPU版本的tensorflow会自动安装依赖的cuda、cudnn动态库以及其他python库,因此使用conda在安装tensorflow的时候可以灵活选择tensorflow版本和cuda版本,装完就能直接跑。
#### 安装方法:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && bash Miniconda3-latest-Linux-x86_64.sh
conda常用命令
配置源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
创建指定python版本下包含某些包的环境
conda create --name your_env_name python=3.5 numpy scipy
列举当前所有环境
conda info --envs
conda env list
进入某个环境
Linux 执行: source activate your_env_name
Windows 执行 activate your_env_name
退出环境
Linux 执行: source deactivate your_env_name
Windows 执行 deactivate your_env_name
复制某个环境
conda create --name new_env_name --clone old_env_name
删除某个环境
conda remove --name your_env_name --all
分享环境
如果你想把你当前的环境配置与别人分享,这样ta可以快速建立一个与你一模一样的环境(同一个版本的python及各种包)来共同开发/进行新的实验。一个分享环境的快速方法就是给ta一个你的环境的.yml文件。
首先通过activate target_env要分享的环境target_env,然后输入下面的命令会在当前工作目录下生成一个environment.yml文件,
conda env export > environment.yml
小伙伴拿到environment.yml文件后,将该文件放在工作目录下,可以通过以下命令从该文件创建环境
conda env create -f environment.yml
当然,你也可以手写一个.yml文件用来描述或记录你的python环境。
包管理
列举当前活跃环境下的所有包
conda list
列举一个非当前活跃环境下的所有包
conda list -n your_env_name
为指定环境安装某个包
conda install -n env_name package_name
如果不能通过conda install来安装,文档中提到可以从Anaconda.org安装,但我觉得会更习惯用pip直接安装。pip在Anaconda中已安装好,不需要单独为每个环境安装pip。如需要用pip管理包,activate环境后直接使用即可。
离线使用步骤:
1、在有网的机器上通过conda把环境装好(主要就是tensorflow、numpy等),需要注意conda本身必须装到/usr/local目录下,完整目录为:/usr/local/miniconda3;
2、然后把/usr/local/miniconda3文件夹打个压缩包;
3、将压缩包cp到U盘,推荐用EXT4格式(Windows下访问用Ext2fsd),默认Linux下不支持NTFS的读写(需要安装ntfs-3g),而FAT32有单个文件4GB的限制;
4、从U盘cp到没有网的机器上,解压到/usr/local/下,完整目录为:/usr/local/miniconda3;
5、配置miniconda的环境变量(export PATH=$PATH:/usr/local/miniconda3/bin)就好了;
6、执行source activate tf 进入tf环境,然后执行python程序即可
传统安装方式
一、卸载原有cuda
参考:https://blog.csdn.net/weixin_40294256/article/details/79173174
$ sudo apt-get remove cuda
$ sudo apt-get autoclean
$ sudo apt-get remove cuda*
$ cd /usr/local
$ sudo rm -rf cuda-9.1
卸载完成后,建议重启一下。
二、安装
step1. 停掉所有与nvidia或者cuda相关进程
参考:https://github.com/NVIDIA/nvidia-docker/issues/62
$ sudo service lightdm stop
$ sudo stop nvidia-digits-server
$ sudo service docker stop
$ sudo rmmod nvidia-uvm
$ sudo service nvidia-docker stop
step2. 下载 .run 安装脚本
如果需要安装其他版本可以打开 https://developer.nvidia.com/cuda-90-download-archive (cuda-90改成你需要的版本)然后下载,然后离线安装
step3. 验证 gcc g++ 版本为 5.4.0
step4. 执行 run 脚本
$ sudo sh cuda_9.1.85_387.26_linux.run
执行过程中,有很多对话框选择,有默认值的选择默认值,没有默认值的选择yes
step5. 恢复安装前停掉的服务
或者
另一种方式(也是最简单的):
wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.2.148-1_amd64.debsudo dpkg -i cuda-repo-ubuntu1604_9.2.148-1_amd64.debsudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pubsudo apt-get updatesudo apt-get install cuda
三、测试cuda
$ cd /usr/local/cuda/samples/1_Utilities/deviceQuery
$ sudo make
$ ./deviceQuery
如果
error: CUDA driver version is insufficient for CUDA runtime version Result=FAIL
则说明没有安装成功。
四、运行nvidia-docker
参考:https://github.com/nvidia/nvidia-container-runtime#docker-engine-setup
五、错误解决
错误 1
apt-get -f install 错误 No apport report written because MaxReports is reached already Errors were...
安装cuda 时提示以下错误,按照要求执行了以后错误任然出现,执行sudo apt-get update和 sudo apt-get upgrade 以后依然是同样的错误。
sudo apt-get upgrade
Reading package lists... Done
Building dependency tree
Reading state information... Done
You might want to run 'apt-get -f install' to correct these.
The following packages have unmet dependencies:
cuda-curand-dev-8-0 : Depends: cuda-curand-8-0 (>= 8.0.64) but it is not installed
cuda-cusolver-dev-8-0 : Depends: cuda-cusolver-8-0 (>= 8.0.64) but it is not installed
cuda-cusparse-dev-8-0 : Depends: cuda-cusparse-8-0 (>= 8.0.64) but it is not installed
cuda-nvgraph-dev-8-0 : Depends: cuda-nvgraph-8-0 (>= 8.0.64) but it is not installed
cuda-nvrtc-dev-8-0 : Depends: cuda-nvrtc-8-0 (>= 8.0.64) but it is not installed
cuda-toolkit-8-0 : Depends: cuda-nvml-dev-8-0 (>= 8.0.64) but it is not installed
E: Unmet dependencies. Try using -f.
在尝试了
sudo apt-get clean
sudo apt-get update
sudo apt-get dist-upgrade
sudo dpkg --configure -a
sudo apt-get install -f
都还存在同样问题时需要手动打开status
sudo vi /var/lib/dpkg/status
然后通过命令行输入 /name 比如 /cuda-curand-8-0 然后按Enter 键(下一个关键字按n)查找文件中的对应模块记录并将其删除(删除按dd),把以上所有模块记录全部删除后 shift+:组合,输入 wq!保存并退出,最后再次执行sudo apt-get install –f 。
错误 2
Ubuntu16.04 由于已经达到 MaxReports 限制,没有写入 apport 报告。
dpkg: 处理软件包 libzbar-dev:amd64 (--configure)时出错:
依赖关系问题 - 仍未被配置
由于已经达到 MaxReports 限制,没有写入 apport 报告。
E: Sub-process /usr/bin/dpkg returned an error code (1)
从网上找到的解决方案为:
$ cd /var/lib/dpkg
$ sudo mv info/ info-bak
$ sudo mkdir info
$ sudo apt-get update
$ sudo apt-get install -f
就解决了问题,然后恢复info-bak
$ sudo mv info/* info-bak/
$ sudo rm -rf info
$ sudo mv info-bak/ info
一切就ok
错误3
Failed to initialize NVML: Driver/library version mismatch
刚刚GPU遇到一个神奇的bug。
运行 nvidia-smi 报错:
Failed to initialize NVML: Driver/library version mismatch
运行nvidia 官方的程序,报错
no CUDA-capable device is detected
如下图:
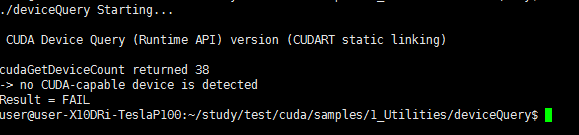
然后解决的办法是: 重启。。。重启。。。
还好虚惊一场,只能说:
Surprise surprise, rebooting solved the issue。